How to move data from MSSQL to ElasticSearch at galactic speeds
Shortly after the one billion mark has been reached with my side project I got a question from an old classmate whether I had ever heard about ElasticSearch. I did, but I’ve never had made any time to dive into it any further. This would be a nice moment to dive into it a bit further. In this post we’ll dive into the data feeding process I used to move some data out of MSSQL and into ElasticSearch.
At first I was a bit skeptical about nosql document storage. I heard good things about the performance of ElasticSearch and I’ve seen and loved Kibana for quick data visualization experiments. So lets jump in.
This post is inspired by / based on the post at https://instarea.com/2017/12/06/heavy-load-ms-sql-elasticsearch/ yet with a bit more code to get you up and running quickly.
We’re assuming that both the MSSQL and ElasticSearch databases are running on localhost. What we’re going to do in a nutshell is to export data from MSSQL to a JSON file and import this file in ElasticSearch.
Preparing the source
Retrieving the data Since MSSQL 2016 it’s possible to export data directly from the database engine. That’s exactly what we’re going to do. There’s a few catches though.
- The documents you want to import should be separated by a newline
- Each document you want to import should be preceded by a command
The following type of command can be used to retrieve data in almost the correct format:
SELECT (SELECT
dbo.ToDateTime2(Ticks) AS 'timestamp'
, Location.Lat AS 'location.lat'
, Location.Long AS 'location.lon'
FOR JSON PATH, WITHOUT_ARRAY_WRAPPER)
FROM dbo.TableName
Every row you select will be a JSON object, or soon to be ElasticSearch document.
Exporting numeric values with a certain accuracy
When exporting numeric data MSSQL is usually trying to be overly accurate (Displaying doubles as `4.782966666666670e+001` for example). ElasticSearch can parse this as numeric data, but it is unable to parse these values as `geo_point` values. Besides this it makes the exported JSON file way bigger then it needs to be.
It is recommended to use the `FORMAT` function to select the number of decimal places you want to show. E.g. `FORMAT(Location.Lat, ‘N5’)` to retrieve a value with an accuracy of 5 decimal places.
You can store the result set from the SQL query in several ways. One way is by copy / pasting the results from the query window in SSMS or whatever your SQL editor is. Personally I find it more convenient, especially with large datasets, to use the bcp command in order to directly output the results to a file. bcp can be used in the following way:
bcp "YOUR SQL QUERY" queryout ./output.json -c -S "SERVER_LOCATION" -d DATABASE_NAME -U "DATABASE_USER" -P "DATABASE_USER_PASSWORD"
Adding commands
Every document which has to be indexed by ElasticSearch should be preceded by a command, though. We want to index the documents, but there are plenty of other commands you can use. See here for a list of commands.
We just use {"index":{}} as a command which tells ElasticSearch we want to index the document. We’ll define the index and type later on while indexing the document.
In order to precede all documents with a command the awk command can be used:
awk '{print "{\"index\":{}}";};1' fileToAddCommandsTo.json > outputFileWithCommandsAdded.json
Importing the data
The resulting document is ready to be imported into ElasticSearch. Depending on the size of the output you might want to chop up the file in bits in order to make sure the bulk import still works.
The following script as found here can be used to chunk up your file and import the data into ElasticSearch. Please note you have to make the following changes to the document:
- The filename which contains the data you want to import. In this case `output.json`.
- The index name in the URL (`[INDEX]`)
- The type name in the URL (`[TYPE]`)
#!/bin/sh
LINES=400000
split -l $LINES output.json
for xf in $(ls | grep x..$)
do
curl -o nul -H 'Content-Type: application/x-ndjson' -XPOST localhost:9200/[INDEX]/[TYPE]/_bulk --data-binary @$xf
rm $xf
done
Hint:
You can save the script above as `import.sh`. Execute it by either running `sh import.sh` or `bash import.sh`. I think either will work. I keep forgetting how to run scripts all the time.
How fast is it?

This fast. Netdata started complaining about the speed the (almost empty 2tb) drive was being written to.
Without joke. It was fast. The file size was about 4.8gb, containing 17,075,262 documents. See the netdata screenshot for the performance hit it took.
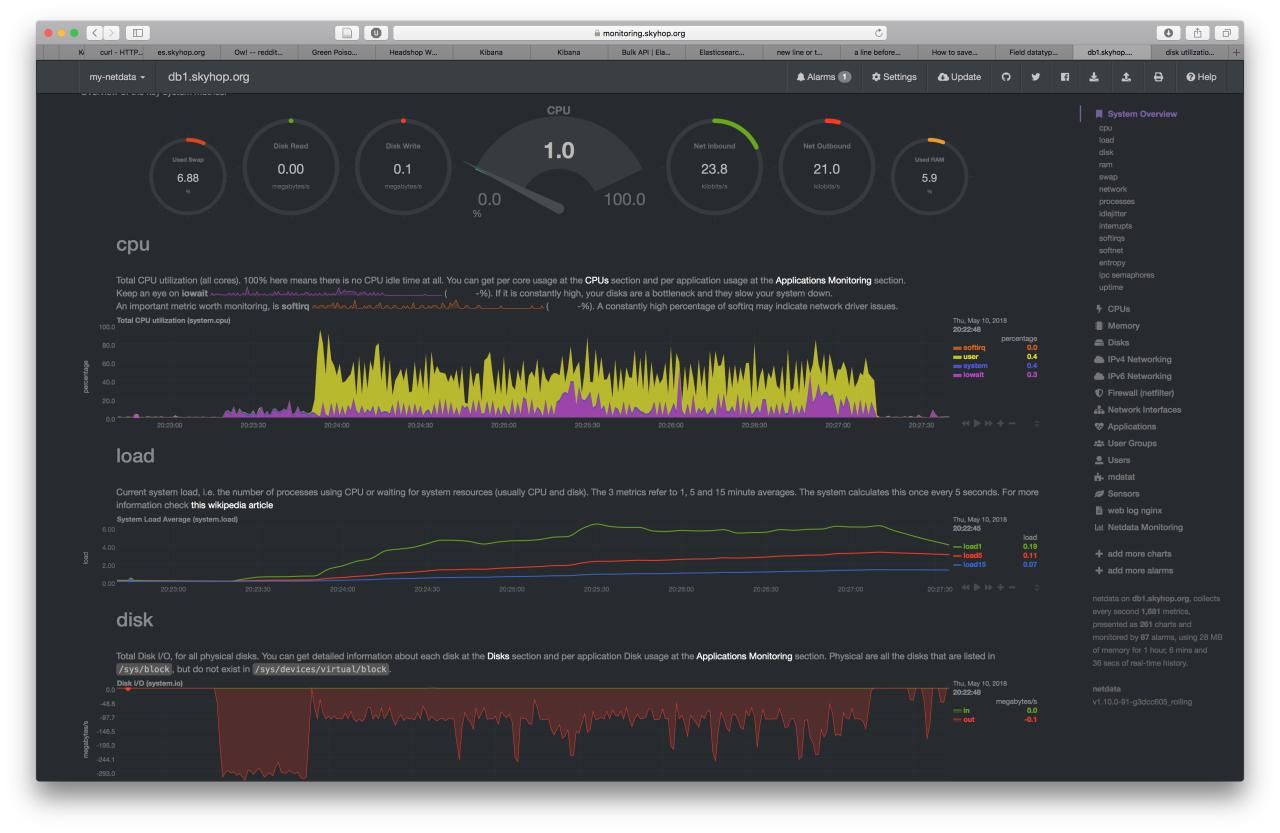
A rough scan shows the import began at 20:23:50 (without slicing the file, that is), and was done at 20:27:15. Which is 205 seconds. Dividing 17,075,262 by 205 amounts to a little more then 83,000 documents each second.
Wanna know about another piece of magic? Check the index size.
corstian@db:~$ curl -XGET "http://localhost:9200/_cat/shards?v"
index shard prirep state docs store ip node
.kibana 0 p STARTED 2 6.8kb 127.0.0.1 VnzjBHy
positions 2 p STARTED 3415189 478.9mb 127.0.0.1 VnzjBHy
positions 2 r UNASSIGNED
positions 3 p STARTED 3415823 477.7mb 127.0.0.1 VnzjBHy
positions 3 r UNASSIGNED
positions 4 p STARTED 3414075 476.3mb 127.0.0.1 VnzjBHy
positions 4 r UNASSIGNED
positions 1 p STARTED 3413247 478.2mb 127.0.0.1 VnzjBHy
positions 1 r UNASSIGNED
positions 0 p STARTED 3416929 479.4mb 127.0.0.1 VnzjBHy
positions 0 r UNASSIGNED
There are five shards with around 480mb of data, which is about 2.4gb. I kid you not, that’s just half the size of the file we’ve just indexed! Ofcourse there’s the overhead in the indexed file of the commands we added but still. That’s truly amazing!