Personal Notes: Writing performant code with C#
This post is a short note of the important takeaways from the talk given by Fons Sonnemans with the .NET Zuid usergroup on the topic of writing performant .NET code. I am not the expert on the topics described below. I’m only recollecting what I learned last night. It’s one of the talks I was super excited about attending, because well, I do have my own performance problem of sorts.
@fonssonnemans I'm super excited for your talk on writing performant code in C# 7 already! ;) pic.twitter.com/O7tBVy11AR
— Corstian Boerman (@CorstianBoerman) August 27, 2018
Fons showed this screenshot of the diagnostic tools to the audience. When I heard someone from the back say “oh shit” I lost it for a brief moment :)
The Garbage Collector
The first and in my humble opinion most interesting part of the talk was about the garbage collector. I know what it is, and what it does, but I did not know about some of the intricate details which are really important. Also, I did not know about the relationship of the garbage collector with the stack and the heap. Heck, I could not even properly explain the difference between the stack and the heap myself.
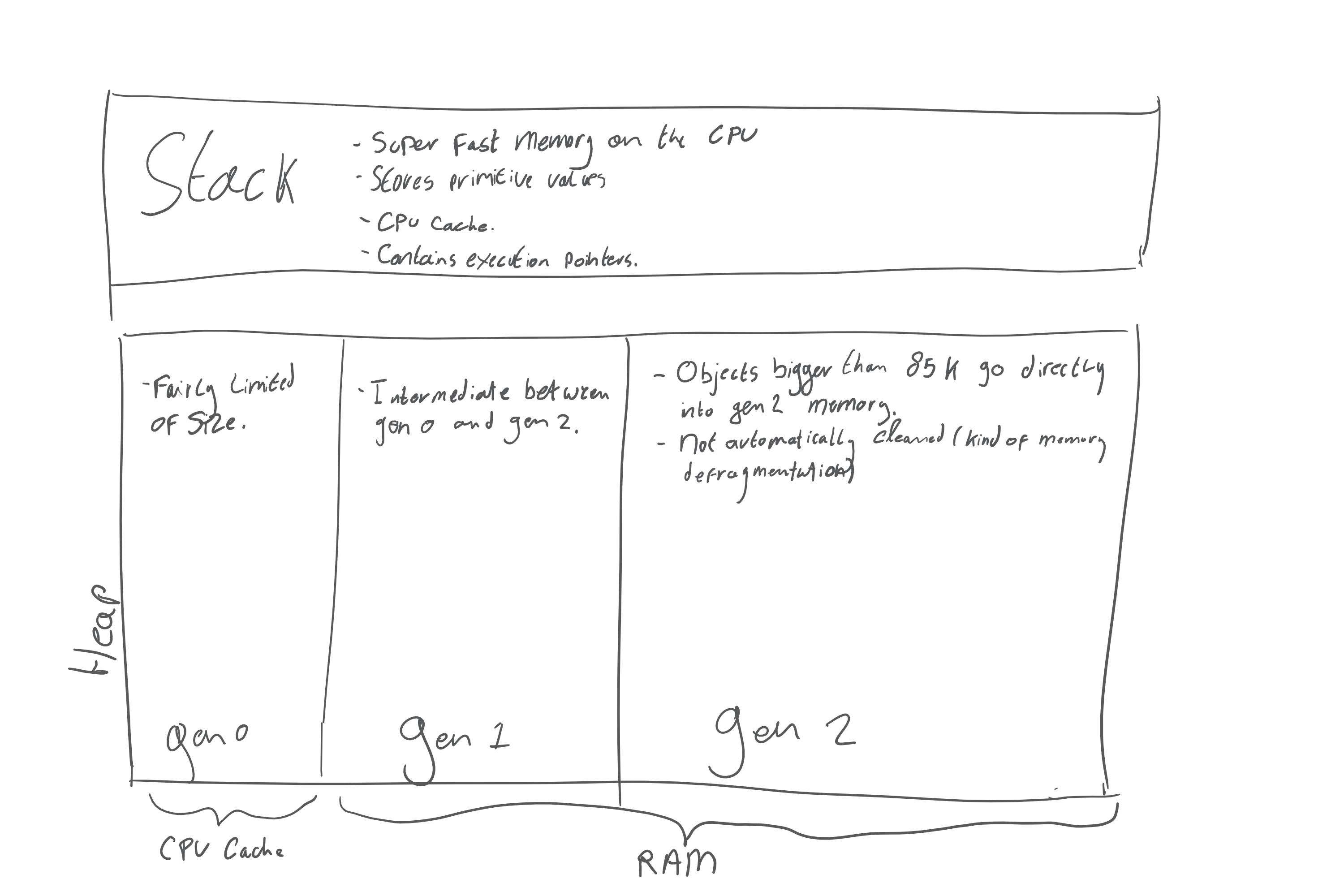
My understanding is currently still limited to a general overview, and I would love to learn a lot more about it in the future, but note that I could be completely wrong on these topics!
Each time the garbage collector runs, data existing in gen 0 and gen 1 is being promoted to the next generation. Copying information like this is definitely expensive. It’s only after last night that I understand what the flyweight pattern is actually useful for.
Running a little code sample (for example in LinqPad) shows how the variables are promoted to following generations:
void Main()
{
int i = 1;
var c1 = new C();
GC.Collect();
var c2 = new C();
GC.Collect();
var c3 = new C();
string s = "";
GC.GetGeneration(i).Dump();
GC.GetGeneration(c1).Dump();
GC.GetGeneration(c2).Dump();
GC.GetGeneration(c3).Dump();
GC.GetGeneration(s).Dump();
}
class C {
public int I { get; set; }
}
While the output is as follows:
0
2
1
0
2
Obviosuly the int stays on the stack (gen 0). The class instances are all being promoted to the next generation with each collection, and the string is immediately promoted to gen 2.
Lists
Everybody loves lists, right? The List<T> object is amazing. It’s flexible, and fast enough for everyday use. Who doesn’t use the .ToList() extension method? It’s safe, right? For developers working a lot with Entity Framework it means that the result set is retrieved and any further processing will be done locally. For others it might mean that the IEnumerable is not enumerated multiple times (which might be a huge performance killer as well).
Apparently the .ToList() (LINQ) extension method is also a huge performance killer. Let me explain.
By default a list is initialized with a capacity of 0. Lists tend to automatically resize, based on whatever is required. Everytime the list is resized this means it is copied around memory, and that is expensive.
Let us time something. What if we create a list with 10 million integers?
var sw = new Stopwatch();
sw.Start();
List<int> ints = new List<int>();
for (var i = 0; i < 10_000_000; i++)
{
ints.Add(i);
}
sw.Stop();
Console.WriteLine(sw.Elapsed.ToString());
Now the execution time of the code is about 0.11 seconds on my machine, while the tool uses 153MB of memory, and during this time about 3 garbage collections have occurred.
If we only could do something to prevent these lists from resizing? Actually we can. The List<T> class has a constructor where you can provide the initial capacity. We’re running the same code now, but we’ve provided the list with a capacity.
Stopwatch sw = new Stopwatch();
sw.Start();
List<int> ints = new List<int>(10_000_000);
for (var i = 0; i < 10_000_000; i++)
{
ints1.Add(i);
}
sw.Stop();
Console.WriteLine(sw.Elapsed.ToString());
Running this snippet takes about 0.05 seconds, with a memory usage of 51MB, without GC collections!
The most difficult thing about this is knowing how many elements will be in the list. To indicate the amount of performance there is to gain, lets assume the capacity would be 16,777,216, while we’re only adding 10 million items. Execution time stays the same, and even seems to be a bit faster (?). Memory footprint is 79MB, and no GC collections have occurred. The while the estimate of the data size is at least 50% off, we’re still only using half the size we would’ve been using if we did not set the initial size explicitly.
Classes vs Structs
Now it gets interesting. From my experience I can tell structs aren’t used so often at all. While extremely beneficial for application performance, developers usually go with classes. Mostly from lack of proper understanding of the differences between these two. The main differences:
- Structs are considered value types, and therefore live (generally) on the stack. Classes are considered reference types and live on the heap.
- Structs do not have inheritance.
- Structs are not nullable.
- Structs have a fixed memory footprint.
Structs usually do live in the stack. That is, until the stack size grows too big and some of it is moved to the heap. Testing this makes that quite clear.
void Main()
{
var s1 = new S();
GC.Collect();
var s2 = new S();
GC.Collect();
var s3 = new S();
GC.Collect();
GC.GetGeneration(s1).Dump();
GC.GetGeneration(s2).Dump();
GC.GetGeneration(s3).Dump();
}
struct S {
int I1 { get; set; }
int I2 { get; set; }
}
Ther resulting output shows that all objects still live in gen 0.
One of the cool things a struct can do which a class can’t is replace itself, due to it’s fixed size.
void Main()
{
var s = new S(1 ,2);
s.I1.Dump();
s.I2.Dump();
s.Switch();
s.I1.Dump();
s.I2.Dump();
}
struct S {
public S(int i1, int i2) {
I1 = i1;
I2 = i2;
}
public int I1 { get; set; }
public int I2 { get; set; }
public void Switch() {
this = new S(I2, I1);
}
}
Upon showing this someone made the comment “Hey, we’re not talking about JavaScript here, right?”.
In the following section the sizes of objects have been determined by using the
System.Runtime.InteropServices.Marshal.SizeOf()method. This method returns the size of an object when it would’ve been marshaled (converted to an unmanaged representation).
Talking about the fixed size of structs, you might be able to shave a few bytes off structs. The following struct will take 8 bytes. Makes sense. 2x 4 bytes.
struct S {
int I1 { get; set; }
int I2 { get; set; }
}
Compare that with the reported size of the following struct (which is 16 bytes).
struct S {
long L1 { get; set; }
int I2 { get; set; }
}
Now it gets fun as the reported data size of the following struct is also 16 bytes!
struct S {
long L1 { get; set; }
int I1 { get; set; }
string S1 { get; set; }
}
But wait! A string is a class right? And besides that, a string can store an amount of data certainly larger than the amount of RAM in your workhorse, right? The trickery that is going on here is that the string is stored as a reference (in the heap), which, because the program runs in 32 bit mode, is 4 bytes long.
Long story short, structs are padded by their biggest data type, which can be observed in awe by checking the size (24 bytes) of the following struct:
struct S {
int I1 { get; set; } // 4 bytes for the int, + 4 bytes for the padding
long L1 { get; set; } // 8 bytes for the long
int I2 { get; set; } // 4 bytes for the int, + 4 bytes of padding
}
The fix is fairly easy. There’s a StructLayoutAttribute which you can use on a struct in the form of [StructLayout(LayoutKind.Auto)] (which doesn’t only work on structs but also on classes). Apparently, due to backwards compatibility, this isn’t being applied by default.
Buffers
With .NET Core (and in Framework through NuGet packages) the [System.Buffers](https://docs.microsoft.com/en-us/dotnet/api/system.buffers) namespace has been introduced. This namespace contains the ArrayPool<T> class which gives you the ability to reserve a section of memory and do all kinds of array/list operations in it. While the array resizing operations stay the same (you should use an initial size where possible anyway) the memory pressure on the garbage collector is significantly smaller, resulting in less collections.
Note that garbage collection can be a blocking operation, and therefore slow the overall performance of your application. See https://docs.microsoft.com/en-us/dotnet/standard/garbage-collection/induced#background-or-blocking-collections for more information about whether garbage collection is blocking or not.
Visual Studio
The speed with which Fons managed to navigate through and work with Visual Studio was (at least for me) astonishing. The takeaways from this:
- VS managed to catch up with ReSharper. I kind of immediately uninstalled ReSharper and so far it’s not like I’m missing anything at all! (Huge performance increase)
- By using ctrl+F5 you can start your program without attaching the debugger. It is so much faster than hitting F5, and having to wait for the debugger to attach. The debugger is truly amazing, but not always required.
- Visual Studio can be an incredible help with generating code. (ctrl+. on a class in order to automagically implement
IEquatableandGetHashCode!) - Visual Studio currently supports so called ‘Analyzers’. These analyzers are tools which can inspect your code in some way and give you hints about what stuff to improve. I have no further knowledge about how they work, but they can help you not to shoot of your feet, or your leg. And oh, a cool thing is that they can be installed on a per-project basis through NuGet packages! ErrorProne.NET (on GitHub) seems like a decent set of analyzers to start with.
Benchmarking
Now, last but not least, know what things cost! For quick experiments you’re most certainly fine with using the StopWatch class and LinqPad. For more thorough tests you might use something more advanced like https://benchmarkdotnet.org/. Again, I’ve heard it exists, and I think it looked nice so I might be interested in using it in the future. For now it’s just important you know it exists.