How can I use cursor based pagination on SQL Server with C#?
Looking for some code examples?
0. Contents
- Introduction
- Requirements
- Proof of conept
3.1OFFSETandFETCH
3.2 The subquery method - Implementation
1. Introduction
On my quest to find an usable form of pagination (for realtime purposes) I learned about cursor based pagination. With this concept you retrieve chunks of data relative to surrounding data. If you are not yet familiar with this concept, check out this answer on StackOverflow which descibes it well and concise.
In this article we will explore one way to implement cursor based pagination for SQL Server. In order to make our lives easier we will continue with some C# code, in which we are going to build a helper method to apply cursor based pagination techniques to (SqlKata) queries.
The C# code will be compliant with .NET Standard 2.0. We will also use SqlKata as a dependency to help us constructing and building the SQL queries.
About using Entity Framework
I have tried using EF Core to implement cursor based pagination, but figured out it was not a viable option at the time of writing due to lack of support for the required methods. In the meantime I have created a feature request for implementingSkipWhile()in the Entity Framework Core repo. Though I realize implementing a single method wouldn’t be sufficient enough to support bidirectional pagination, but would be a start.
2. Requirements
Cursor based pagination (as described in the GraphQL Relay specification) consists of four arguments which are resolved in a certain way:
after: The cursor defining the beginning of the slicefirst: The number of items to get from the beginning of the slicebefore: The cursor to define the end of the slicelast: The number of items to get from the end of the slice
The goal is to resolve these four arguments in a way that we can take a query, and apply these slicing arguments regardless of the contents of said query. One of the more important implementation details is that we should be able to order our resultset however we want, and the cursor should (usually) be based on the primary key.
Although GraphQL is no part of this post, we’re mostly following the GraphQL Relay spec detailing how these four arguments should be resolved.
Check out paragraph 2.3 from my article “Implementing pagination with GraphQL.NET and Relay” for more details.
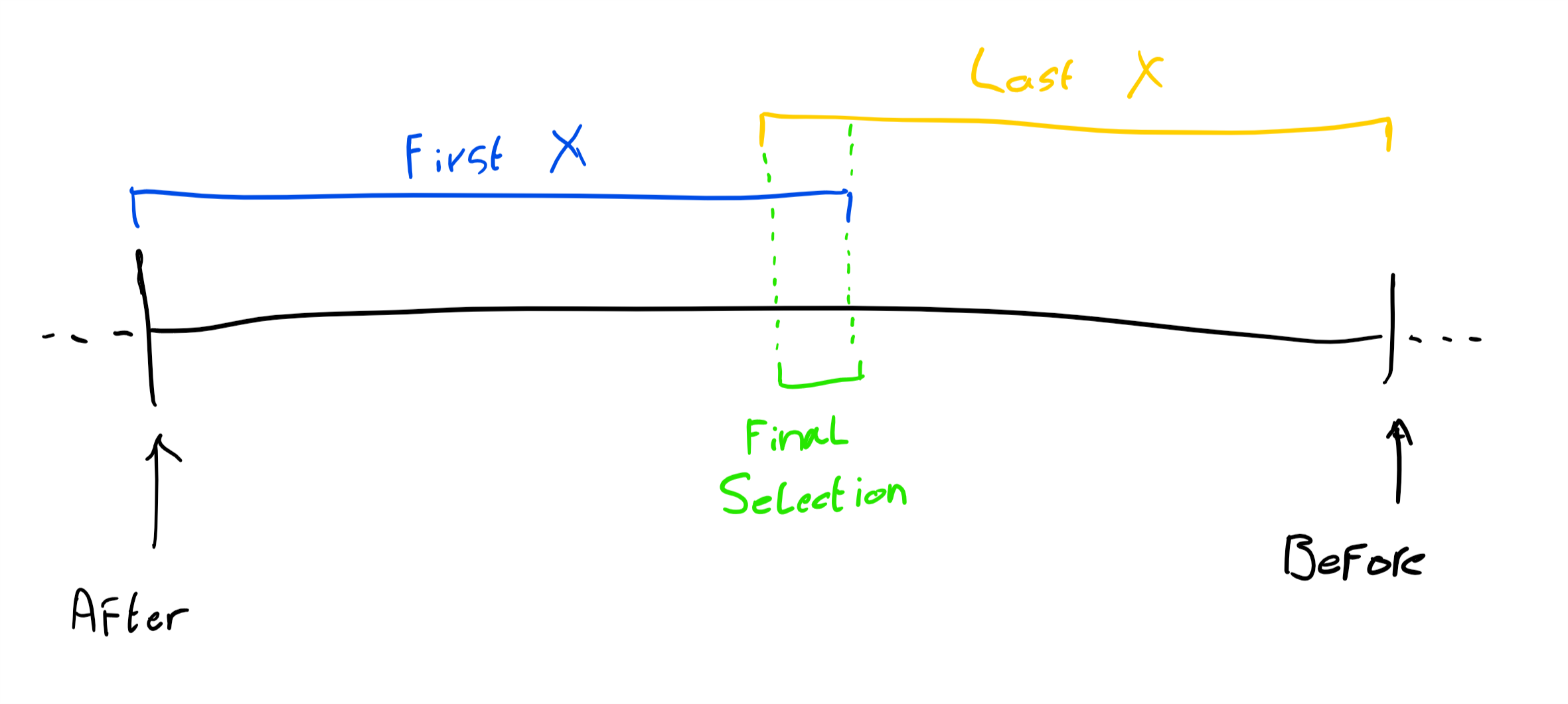
Note that the implementation we’re creating deviates from the specification in the way that combined usage of the first and last properties is handled differently. This implementation will select the overlap between these two properties based on the used cursors, if applicable. See the sketch below:
3. Proof of concept
Just to verify we can do cursor based pagination with SQL Server at all, we did some experiments to see whether SQL Server would be capable enough to suit our needs. With two possible, and somewhat generic options available we went on to see which would best suit our needs.
The cornerstone of both methods involves the ROW_NUMBER() function. This function numbers all rows according to the provided order arguments. Note that this function starts numbering records at 1.
3.1 OFFSET and FETCH
The first method is the method shown below. We rely on the OFFSET and FETCH methods to retrieve our data in the specified slices.
Note that [Query] is defined as a CTE (Common Table Expression).
SELECT * FROM [Query] ORDER BY [Timestamp] DESC OFFSET (
SELECT TOP 1 [RowNumber]
FROM (
SELECT
[Query].Id,
ROW_NUMBER() OVER(ORDER BY [Timestamp] DESC) AS [RowNumber]
FROM [Query]
) [Temp]
WHERE [Temp].Id = '0b12d2c9-1c38-4ffe-8177-0671c5d3b709'
) ROWS
FETCH NEXT 20 ROWS ONLY
The idea is that we’re building a sorted index of our data in-memory. This approach requires minimal mutation of the query we are working with. However, this method would have the following implications:
- The query provided to our extension method shall be stripped of any
ORDER BYclauses. The stripped clauses will be used in our query (as you can see in the example above). - Besides inability to use
ORDER BYclauses in this code, all other limitations that come with the use of CTEs (Common Table Expressions) apply.
Another implication of this method is that we cannot easily iterate backwards over our data-set. While the FETCH documentation mentions a PRIOR keyword, we cannot use this as it requires an active cursor, which involves locking records for data retrieval. On of the only available options to possibly mitigate this would be to invert the ORDER BY clauses.
Therefore I conclude this method is not suitable for one of the following argument combinations:
firstandlast: Not really interesting most of the time anywaybeforeandafter: Might come in handy from time to time
3.2 The subquery method
The second approach involves butchering the query in order to include an additional (RowNumber) field. With this field injected into the CTE we get the ability to query more flexibly.
While I did not run any benchmarks, some rough timing that the CPU time on this method is slightly higher than with the offset/fetch method, but the elapsed time is usually cut in half.
Resulting queries look a bit like the one below. Each of the four arguments will resolve to a WHERE clause which checks the RowNumber field.
SELECT *
FROM [Query]
WHERE [RowNumber] > (
SELECT [RowNumber]
FROM [Query]
WHERE [Id] = '136f30f6-cf73-4754-a1cf-aecf4d6f6cd7')
AND [RowNumber] < (
SELECT [RowNumber]
FROM [Query]
WHERE [Id] = '05528934-DE90-43AF-ABE3-8535433FE53A')
As with the offset/fetch method we have to remove the ORDER BY clauses. This time however we will inject the order statements back into the CTE as part of our ROW_NUMBER selection (see beneath).
ROW_NUMBER() OVER(ORDER BY [Timestamp] DESC) AS RowNumber
The amazing thing about this approach is that we can get bloody fast results when we know the exact row numbers to query, this however is not usually the case. Even then this method is faster than the offset/fetch method discussed earlier, and we have the flexibility to slice our data however we want by using the four arguments as described in chapter 2.
Even then, this method is faster than the offset/fetch method, and we’re quite flexible to implement this however we want it to.
4. Implementation
In order to limit complexity throughout the application we aim for an extension method which can be used in a generic way. In order to achieve this we can impossibly depend on the contents of the query. However due to the dynamic nature of the query argument we are required to make certain assumptions:
- The query cannot contain a CTE
- The query is required to contain
ORDER BYclauses - The query cannot contain an object named
RowNumberfor it would be ambiguous
Heads-up: As I am no expert on SQL, these are two obvious cases on the top of my mind. There are probably many more catches, but this framework should suffice for most of your everyday query slicing needs.
The Slice method also does not return a data-set. Doing so would require tight coupling between query generation logic and some information about the database (credentials etc), which we are trying to stay away from.
[Pure]
public static Query Slice(
this Query query,
string after = null,
int first = 0,
string before = null,
int last = 0,
string column = "Id")
{
var queryClone = query.Clone();
// Manually compile the order clauses for later use in the query
var order = new SqlServerCompiler()
.CompileOrders(new SqlResult
{
Query = queryClone
});
queryClone.Clauses.RemoveAll(q => q.Component == "order");
if (string.IsNullOrWhiteSpace(order))
throw new Exception($"{nameof(query)} does not have an order by clause");
queryClone.SelectRaw($"ROW_NUMBER() OVER({order}) AS [RowNumber]");
var internalQuery = new Query()
.With("q", queryClone)
.From("q");
// Select all rows after provided cursor
if (!String.IsNullOrWhiteSpace(after))
{
internalQuery.Where("RowNumber", ">",
new Query("q")
.Select("RowNumber")
.Where(column, after));
}
// Select all rows before provided cursor
if (!String.IsNullOrWhiteSpace(before))
{
internalQuery.Where("RowNumber", "<",
new Query("q")
.Select("RowNumber")
.Where(column, before));
}
// Select the first x amount of rows
if (first > 0)
{
// If the after cursor is defined
if (!String.IsNullOrWhiteSpace(after))
{
internalQuery.Where("RowNumber", "<=",
new Query("q")
.SelectRaw($"[RowNumber] + {first}")
.Where(column, after));
}
// If no after cursor is defined
else
{
internalQuery.Where("RowNumber", "<=", first);
}
}
// Select the last x amount of rows
if (last > 0)
{
// If the before cursor is defined
if (!String.IsNullOrWhiteSpace(before))
{
internalQuery.Where("RowNumber", ">=",
new Query("q")
.SelectRaw($"[RowNumber] - {last}")
.Where(column, before));
}
// If we have to take data all the way from the back
else
{
internalQuery.Where("RowNumber", ">",
new Query("q")
.SelectRaw($"MAX([RowNumber]) - {last}"));
}
}
return internalQuery;
}
Note that the SqlKata library does not have pure functions for performance reasons. While I usually choose to use the same conventions when writing extension methods for a specific library or framework, it would not make sense to do so in this case. The
Queryobject is mutated in such a specific way that the only use case for a non-pure function would be to introduce obscure bugs.
The techniques described in this article came to be after a lot of fiddling by trial and error. Given my lack of experience writing SQL I am aware that there are most certainly optimization available to this logic. If you know about an optimization or improvement to this code, please let me (us) know!